Paso 1
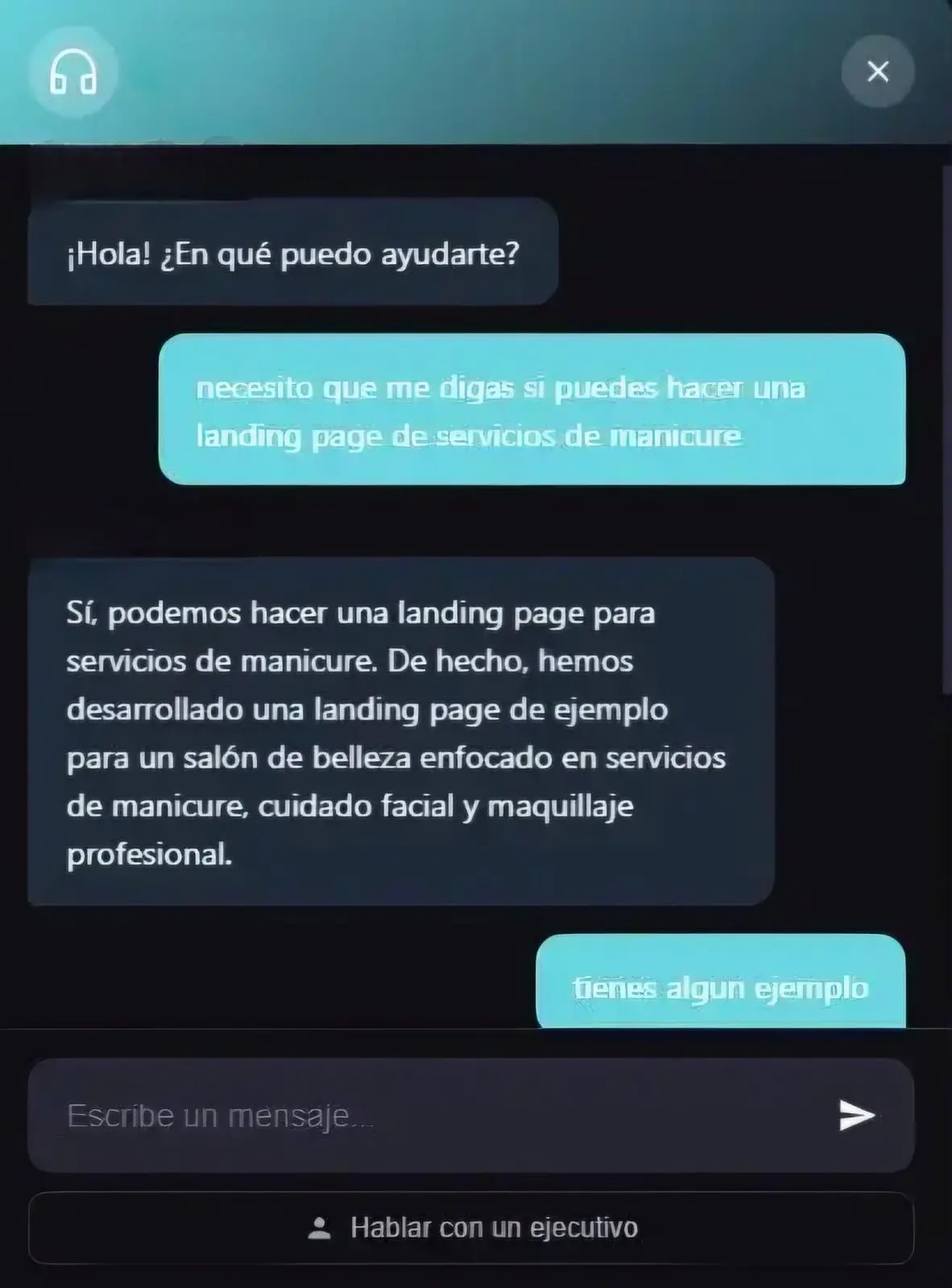
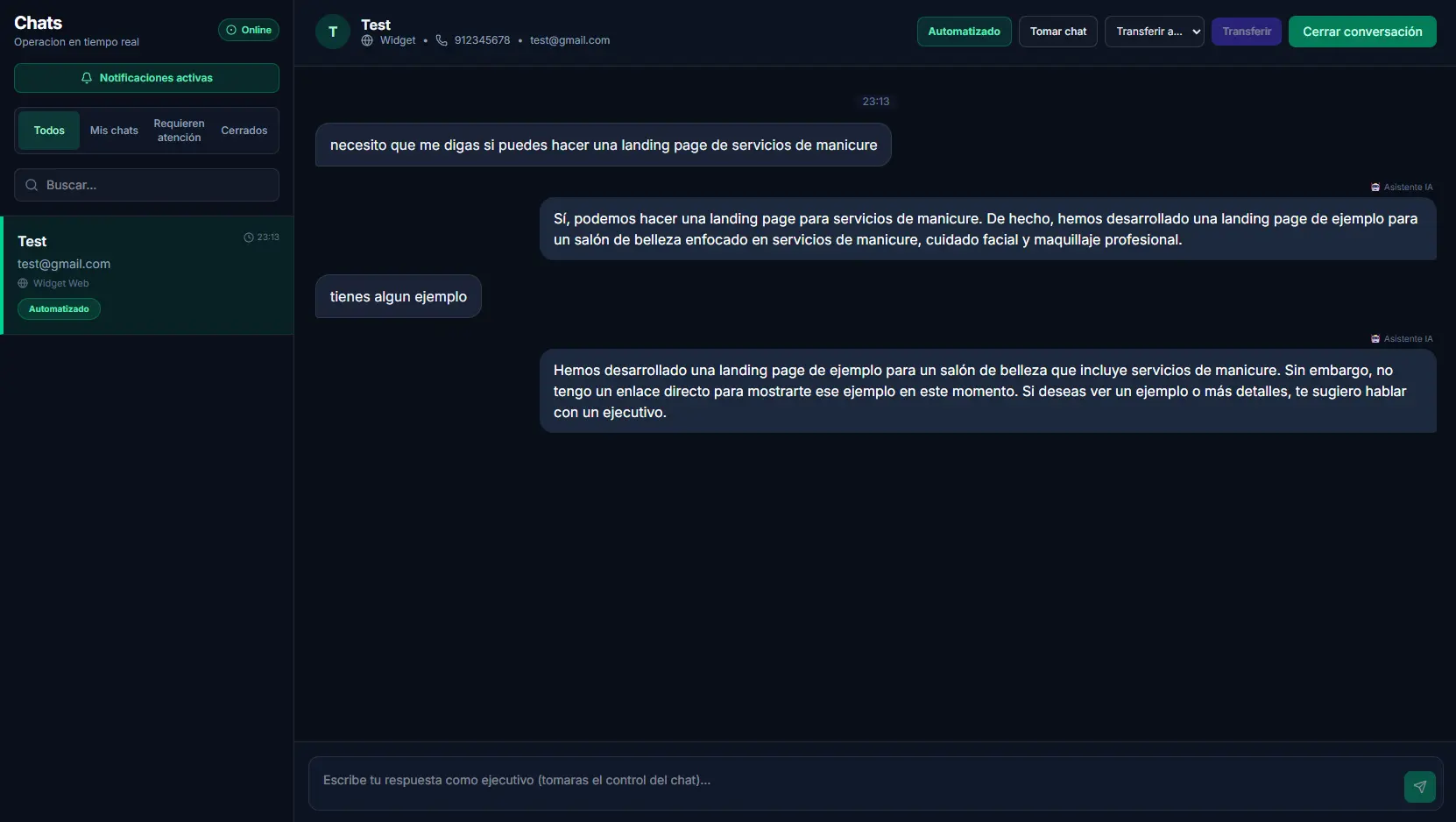
Captura de lead en tu web
El visitante completa nombre, correo y teléfono desde el widget interactivo.
Plataforma SaaS conversacional multi-tenant con IA, handoff humano en tiempo real y arquitectura extensible por adapters.
No es solo "una app con IA" — es una plataforma operable y defendible técnicamente.

Aviso Importante: Si te logueas y no carga nada, es porque no pagué el servidor.
El visitante completa nombre, correo y teléfono desde el widget interactivo.
Negocios pierden leads por respuestas lentas. No hay continuidad entre canales y falta trazabilidad de conversaciones.
IA 24/7 con RAG + handoff humano inteligente. Widget embebible, dashboard operativo y soporte WhatsApp. Todo multi-tenant con control por planes.
Objetivos operativos y benchmarks en entorno demo para validar la arquitectura.
Tiempo a primera respuesta
Sub-2s
Streaming visible desde el primer token cuando hay contexto.
Handoff humano
1 clic
Escalado inmediato cuando hay agentes online.
Onboarding
3 pasos
Script + token + listo para producir leads.
Escala multi-tenant
Rooms + RLS
Aislamiento por tenant en sockets y datos.
3 aplicaciones desacopladas que se comunican por REST + WebSocket.
API REST, WebSocket realtime, orquestación IA con RAG, function calling y persistencia Supabase.
Panel operativo para agentes con chats en tiempo real, RBAC, knowledge base y configuración de integraciones.
Chat embebible en sitios de terceros vía loader.js + iframe. Streaming de respuestas y transición a humano.
Navega, haz zoom y arrastra los nodos para explorar cómo se conectan los componentes del sistema.
Desde que un visitante envía un mensaje hasta que recibe respuesta de la IA o un agente humano.
El sitio cliente carga loader.js que inserta un iframe con la configuración del tenant.
El widget se conecta al namespace /widget con sessionId y datos del visitante.
El backend busca contexto relevante (embeddings), lo inyecta a Gemini junto con el historial y responde en streaming en tiempo real.
Si Gemini detecta que necesita una herramienta (ej. calendario), emite un function call → Factory enruta al Adapter activo → resultado se inyecta de vuelta.
Trigger explícito o por heurística de
frustración. Se valida horario, cambia status a human, notifica dashboard con push y un agente toma
el chat.
Diseñado para que el equipo responda rápido y el cliente sienta continuidad.
Decisiones arquitectónicas que hacen la plataforma extensible y mantenible.
Agregar integraciones (Calendar, WhatsApp) sin tocar el core de IA. Contrato común para APIs heterogéneas.
Realtime desacoplado con Socket.io: namespaces /widget y /dashboard, rooms por tenant y chat.
Auth, CORS, rate-limit y tenant context aplicados transversalmente antes de cada request.
Si falla push, calendar o un subsistema externo, la conversación continúa. Backoff aplicado en ingesta RAG (embeddings).
Decisiones de operación que permiten crecer sin reescribir.
Controles operativos para mantener servicio estable y predecible.
Siguientes iteraciones para elevar la calidad del agente y su operación en producción.